FK 유무에 따른 성능 비교
FK 유무에 따른 성능 비교
“같은 모듈 내에서는 JPA 연관 매핑을 이용해 직접 참조하고, 다른 모듈 간에는 식별자(PK)만 저장하는 간접 참조를 적용하며, 데이터베이스 레벨에서는 외래키 제약을 사용하지 않는다.”는 최근 개발 중인 SW프로젝트관리시스템에서 정했던 Convention 중 하나이다. 직접 참조와 간접 참조는 무엇일까? 백엔드 팀은 개념의 혼동을 막기 위해 JPA에서의 직접 참조와 간접 참조에 대해 정의했다.
- 직접 참조 : JPA 매핑을 통해 엔티티 간에 직접 연관관계를 맺는 방식
- 간접 참조 : 연관 매핑 없이, 다른 엔티티의 식별자(PK)만을 저장하여 참조하는 방식
1. 시작하며
위 사진은 테이블 중 일부이다. 앞서 설명한 Convention에서 FK를 사용하지 않는다고 했는데 세미나 준비를 위해 현재 DB의 다이어그램을 확인해보니 FK가 걸려있었다. 이것은 SQL문을 따로 만들지 않고 ddl-auto: update 로 설정해서 자동으로 FK가 걸린 듯하다.
문득 FK가 있을 때와 없을 때의 성능 차이가 궁금해졌다. FK는 참조 무결성을 보장하고 데이터의 일관성을 유지한다. 하지만 성능 향상을 위해 FK를 제거했을 때, 성능이 얼마나 향상될까?
2. 데이터 삽입 성능 테스트
방법
- FK가 있는 버전의 스키마, FK가 없는 버전의 스키마를 준비한다.
- 테스트 대상 테이블은
Team과TeamComment테이블로 정한다.
- 테스트 대상 테이블은
- 부모 데이터 삽입 진행 (초기화 → 100,000건 삽입)
- 자식 데이터 삽입 진행 (초기화 → 1,000,000건 삽입)
<schema.sql → FK 有>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
...
CREATE TABLE `team` (
`id` bigint NOT NULL AUTO_INCREMENT,
`created_at` datetime(6) DEFAULT NULL,
`updated_at` datetime(6) DEFAULT NULL,
`github_path` varchar(255) DEFAULT NULL,
`is_deleted` boolean NOT NULL,
`is_submitted` boolean NOT NULL,
`leader_name` varchar(255) NOT NULL,
`overview` varchar(3000) DEFAULT NULL,
`project_name` varchar(255) NOT NULL,
`team_name` varchar(255) NOT NULL,
`you_tube_path` varchar(255) DEFAULT NULL,
`contest_id` bigint NOT NULL,
`production_path` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `team_comment` (
`id` bigint NOT NULL AUTO_INCREMENT,
`created_at` datetime(6) DEFAULT NULL,
`updated_at` datetime(6) DEFAULT NULL,
`description` varchar(255) NOT NULL,
`is_deleted` boolean NOT NULL,
`member_id` bigint NOT NULL,
`team_id` bigint NOT NULL,
PRIMARY KEY (`id`),
KEY `FKgtnhqij07nwerilfnnre` (`team_id`),
CONSTRAINT `FKgtnhqij07asdfae44569xcdfkq`
FOREIGN KEY (`team_id`) REFERENCES `team` (`id`)
);
...
<schema.sql → FK 無>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
...
CREATE TABLE `team` (
`id` bigint NOT NULL AUTO_INCREMENT,
`created_at` datetime(6) DEFAULT NULL,
`updated_at` datetime(6) DEFAULT NULL,
`github_path` varchar(255) DEFAULT NULL,
`is_deleted` boolean NOT NULL,
`is_submitted` boolean NOT NULL,
`leader_name` varchar(255) NOT NULL,
`overview` varchar(3000) DEFAULT NULL,
`project_name` varchar(255) NOT NULL,
`team_name` varchar(255) NOT NULL,
`you_tube_path` varchar(255) DEFAULT NULL,
`contest_id` bigint NOT NULL,
`production_path` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE `team_comment` (
`id` bigint NOT NULL AUTO_INCREMENT,
`created_at` datetime(6) DEFAULT NULL,
`updated_at` datetime(6) DEFAULT NULL,
`description` varchar(255) NOT NULL,
`is_deleted` boolean NOT NULL,
`member_id` bigint NOT NULL,
`team_id` bigint NOT NULL,
PRIMARY KEY (`id`)
);
...
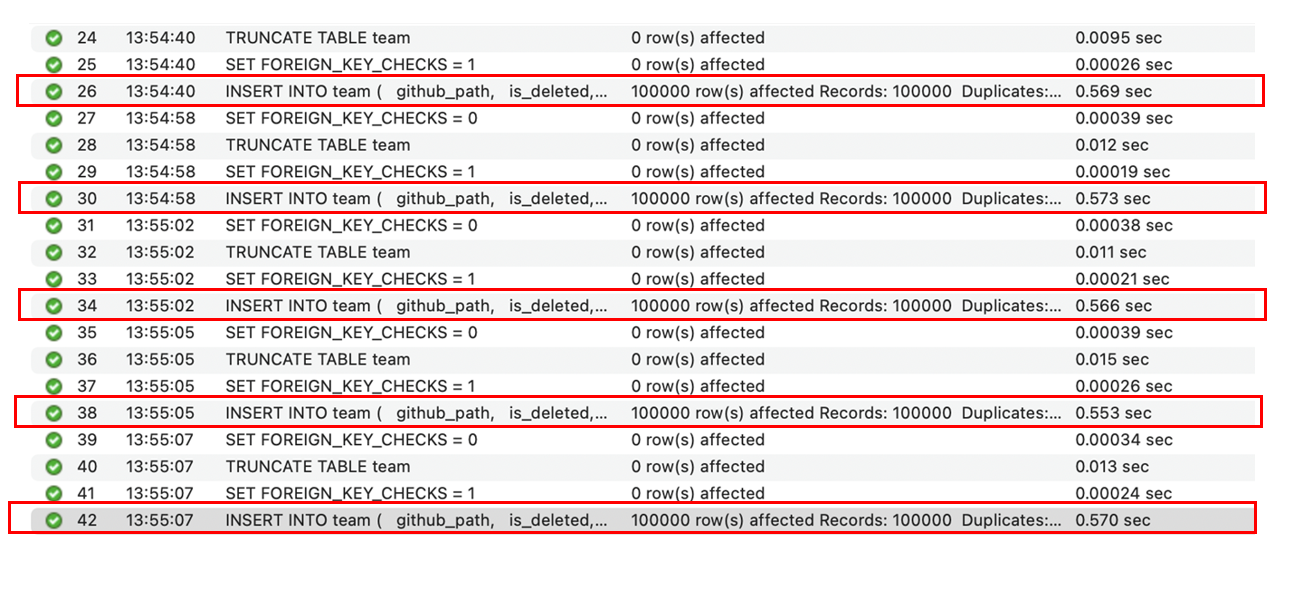
결과 - 1 (FK 有 & 부모 데이터 100,000건 삽입)
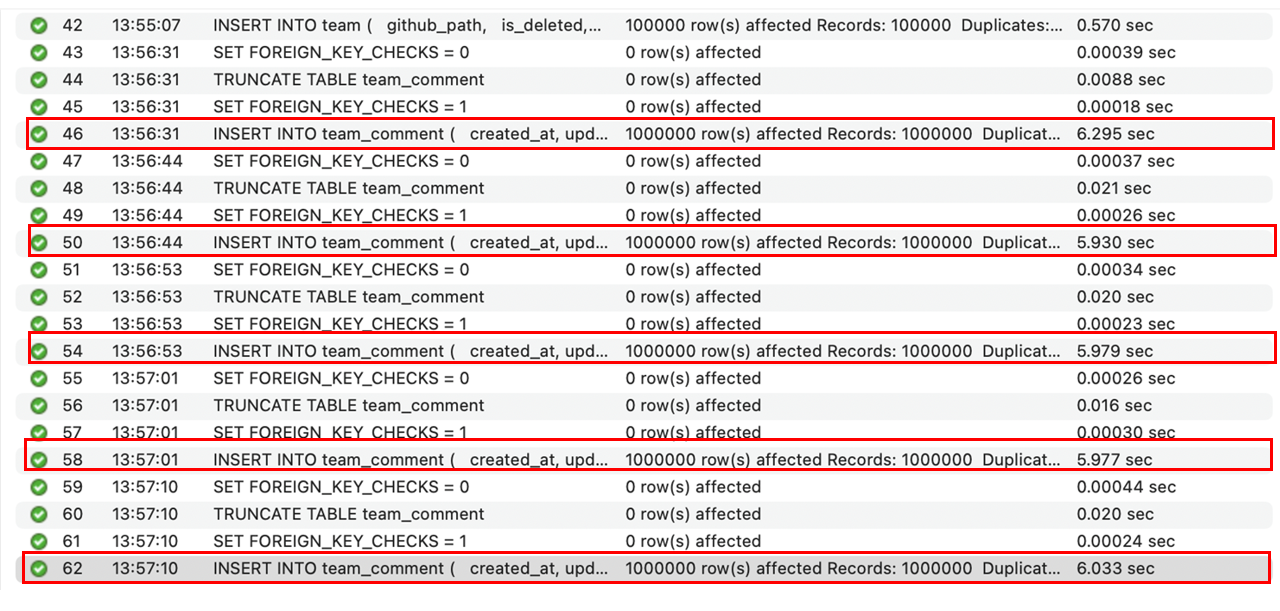
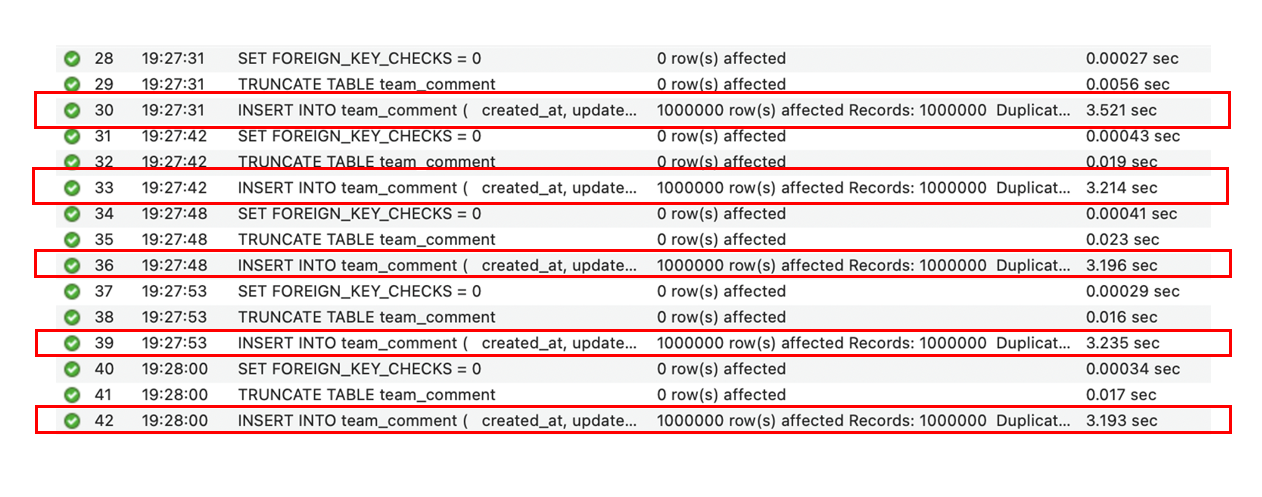
결과 - 2 (FK 有 & 자식 데이터 1,000,000건 삽입)
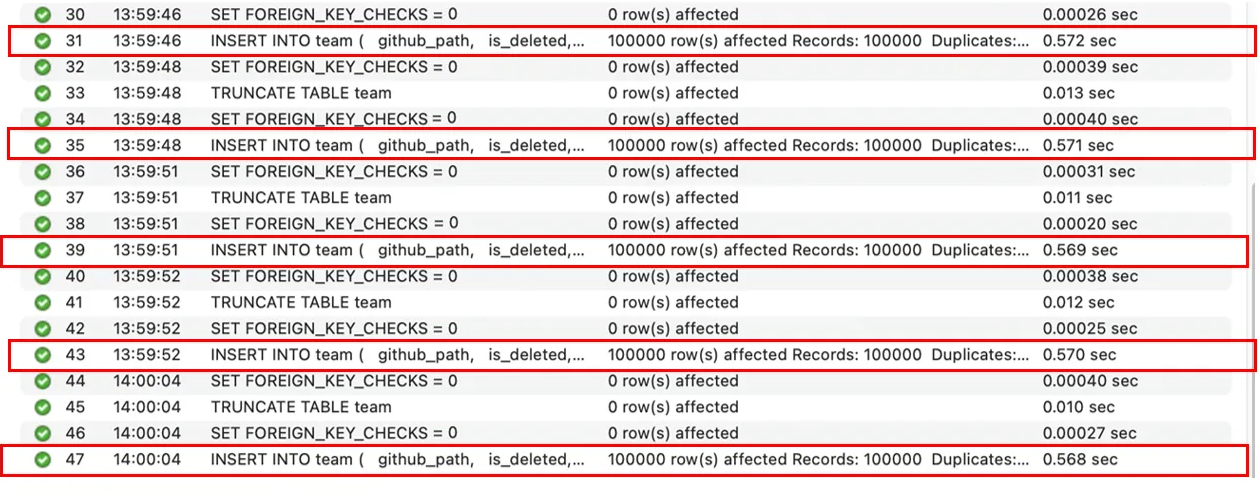
결과 - 3 (FK 無 & 부모 데이터 100,000건 삽입)
결과 - 4 (FK 無 & 자식 데이터 1,000,000건 삽입)
⭐️ 정리
<부모 데이터>
| 평균 시간 (s) | 표준 편차 (s) | |
|---|---|---|
| FK 有 | 0.566 | 0.007 |
| FK 無 | 0.569 | 0.002 |
<자식 데이터>
| 평균 시간 (s) | 표준 편차 (s) | |
|---|---|---|
| FK 有 | 6.043 | 0.130 |
| FK 無 | 3.272 | 0.126 |
- 부모 테이블 삽입 : FK 유무와 무관함
- 자식 테이블 삽입 : FK 없을 때 약 45.9% 빠름
FK가 없을 때 삽입 속도가 빨라진 것에는 많은 이유가 있지만 주된 이유는 부모 테이블 존재 확인 여부 때문이다.
- DB가 부모 테이블의 해당 PK 인덱스를 조회해 “이 팀(team)에 해당하는 레코드가 실제로 있나?”를 확인한다.
- 하지만 FK가 없다면 이 검증 단계 자체가 사라지므로, 부모 테이블을 참조하기 위한 인덱스 조회 비용이 완전히 줄어든다.
3. 벤치마크 시나리오
방법
- SELECT-JOIN → 10,000회 (목표 :
team↔team_commentJOIN 성능 비교) - UPDATE → 10,000회 (목표 :
team_comment의 대량 UPDATE 성능 비교) - DELETE → 10,000회 (목표 : FK 유무에 따른 Delete 처리 비교)
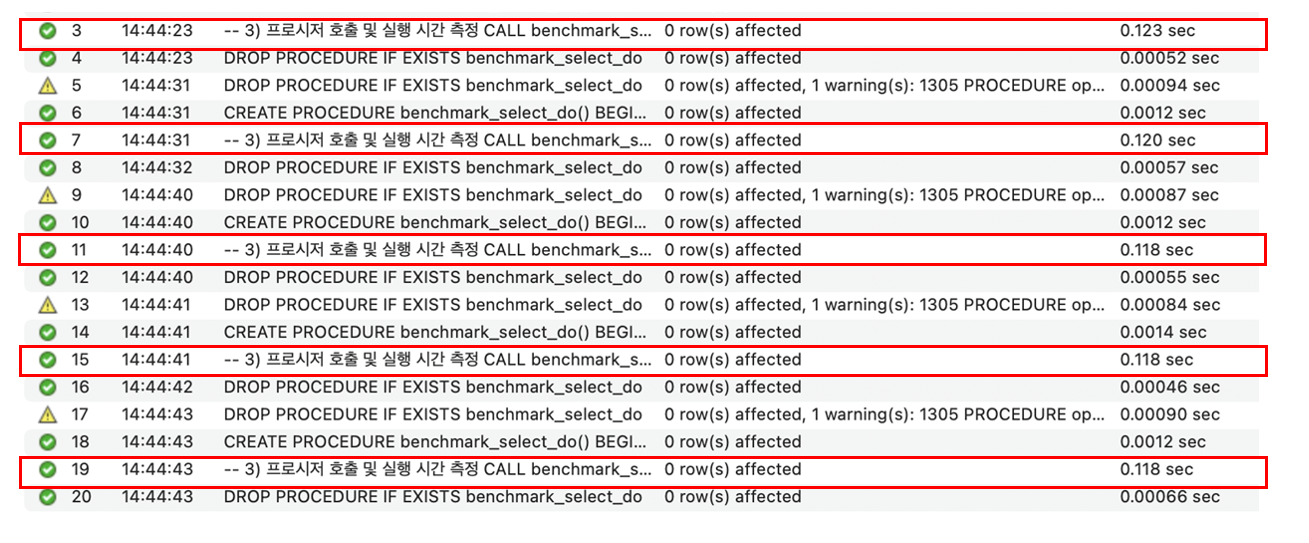
결과 - 1 (FK 有 & SELECT-JOIN)

<발생한 문제>
⇒ select query를 10,000번 호출해서 결과 탭이 10,000개 만들어져서 최대 결과 탭 수 초과
- DO 문을 사용해서 해결 (Mysql 8 이상)
결과 - 2 (FK 無 & SELECT-JOIN)
결과 - 3 (FK 有 & UPDATE)

결과 - 4 (FK 無 & UPDATE)

결과 - 5 (FK 有 & DELETE)
- Cascade로 자동 삭제

결과 - 6 (FK 無 & DELETE)
- 삭제 쿼리 2번

⭐️ 정리
<SELECT‑JOIN>
| 평균 시간 (s) | 표준 편차 (s) | |
|---|---|---|
| FK 有 | 0.143 | 0.003 |
| FK 無 | 0.119 | 0.002 |
- SELECT-JOIN 같은 경우 FK와 연관 없으므로 큰 차이를 보이지는 않았다.
<UPDATE>
| 평균 시간 (s) | 표준 편차 (s) | |
|---|---|---|
| FK 有 | 0.757 | 0.019 |
| FK 無 | 0.590 | 0.005 |
- FK가 없는 경우 약 28% 빠름
- 단순 컬럼 업데이트만 진행되지만, FK가 있으면 존재 검증과 lock 단계가 추가된다.
<DELETE>
| 평균 시간 (s) | 표준 편차 (s) | |
|---|---|---|
| FK 有 | 0.108 | 0.003 |
| FK 無 | 0.147 | 0.004 |
- FK가 있는 경우 약 26% 빠름
- 한 번의 쿼리로 연쇄 삭제가 가능하지만, FK가 없으면 부모·자식 삭제에 각각 쿼리가 두 번 나간다.
4. 결론
주요 결과는 다음과 같다.
- Insert는 FK가 없을 때 45.9%의 효율을 보인다.
- Delete는 FK가 있을 때 26%의 효율을 보인다.
Delete 실험 전에는 FK 없이 두 번의 삭제 쿼리가 나가더라도 cascade연산보다 더 빠를 거라 생각했다.
하지만 실제 측정 결과 한 번의 호출이 더 효율적인 것을 확인할 수 있었다.
이 결과를 바탕으로 우리 팀은 다음과 같이 정리했다.
- 현재 Convention을 유지한다.
- SW프로젝트관리시스템은 soft delete를 사용하므로 cascade option을 사용하지 않는다. 따라서 Delete와 cascade 관련 실험 결과는 시스템 성능과 무관하다.